In this chapter, we explore the features provided by Elasticsearch that can be used to build a agile time series database. We can see how good experience from existing solutions can be applied to Elasticsearch, also how to mitigate the problems of existing solutions.
Architecture
To answer query like
SELECT AVG(age) FROM login WHERE timestamp > xxx AND timestamp < yyy AND site = 'zzz'
The query need to go through three things (in RDBMS terms):

In Mysql, the three steps are:
- look up the filters in its b-tree index, and found a list of row ids
- use the row ids to retrieve rows from the primary row store
- compute the group by and projections in memory from the loaded rows
Using Elasticsearch as a database is very similar:
- look up the filters in its inverted index, found a list of document ids
- use the document ids to retrieve the values of columns mentioned in projections
- compute the group by and projections in memory from the loaded documents
Conceptually despite Elasticsearch is a full-text index not a relational database, the process are nearly identical. The differences are:
- Elasticsearch is using inverted index instead of b-tree index to process filters
- Mysql row is called document in Elaticsearch
- Mysql has only one way to load the whole row from row store using row ids, Elaticsearch has 4 different ways to load the values using document ids
Elaticsearch is faster and more scalable than mysql for time series data because:
- Inverted index is more efficient to filter out large number of documents than b-tree index
- Elasticsearch has a way to load large number of values using the document ids efficiently, mysql does not which makes its b-tree index useless in this context
- Elasticsearch has a fast and sharded in memory computation layer to scale out, and there are optimization to bring in SIMD to optimize the speed further
Let's go through them one by one, I am sure you will love Elasticsearch.
Finite State Transducers (FST)
There is one article that explains inverted index very well: http://blog.parsely.com/post/1691/lucene/
The example from the article illustrated what is inverted index very well:
doc1={"tag": "big data"}
doc2={"tag": "big data"}
doc3={"tag": "small data"}
The inverted index for the documents looks like:
big=[doc1,doc2]
data=[doc1,doc2,doc3]
small=[doc3]
b-tree index is not that different from end-user perspective, b-tree also invert the rowid=>value to value=>rowid, so that find rows contains certain value can be very fast.
There is a great article on how inverted is stored and queried using Finite State Transducers http://www.cnblogs.com/forfuture1978/p/3945755.html
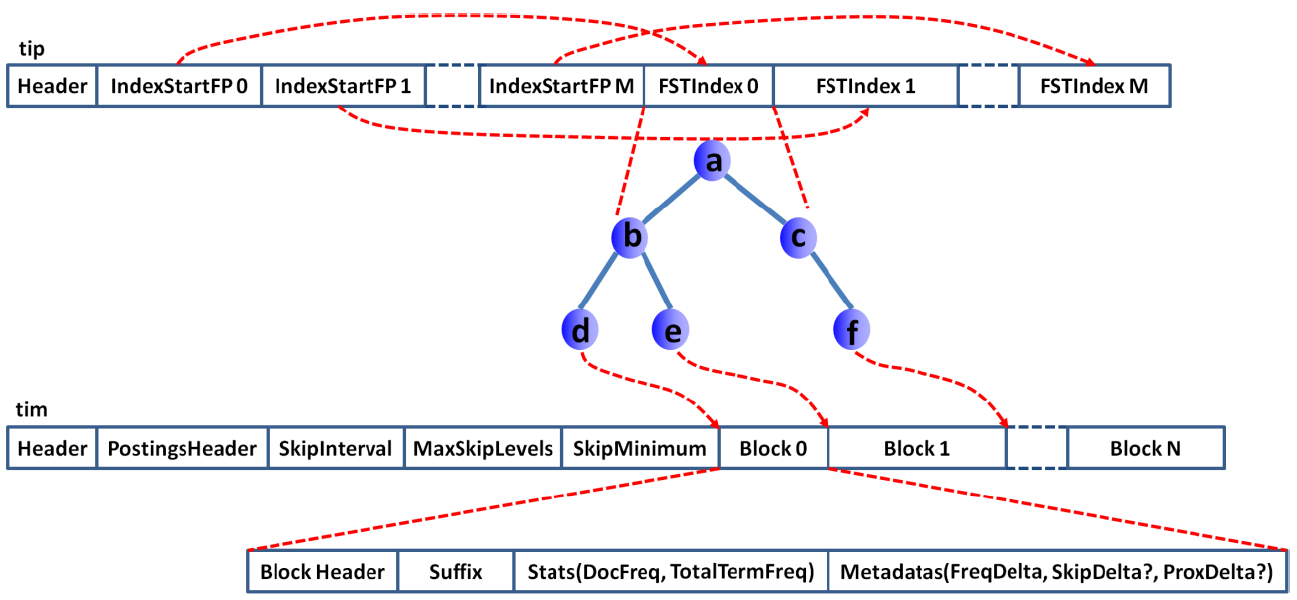
For people do not have time to read the article or lucene source code. It works like English dictionary. You look up the section, find the chapter, than find the material you are looking for.
Numeric Range Query
Numeric data can also be indexed, looks like:
49=[doc31]
50=[doc40,doc41]
51=[doc53]
...
This is fine for point query. But if querying for a range, it will be slow. Optimization is done to speed up the range query:
49=[doc31]
50=[doc40,doc41]
50x75=[doc40,doc41,doc53,doc78,doc99,...]
51=[doc53]
...
To query 50 ~ 100
50x75 OR 76x99 OR 100
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-core-types.html#number there is a setting precision_step to control how many terms generated. If no range query is required, we can set it to max to save disk space.
Bitset
In mysql, if you have two columns and you have query like "plat='wx' AND os='android'" then using b-tree index to index plat and os is not enough. In the runtime, if you have index for column plat and another index for column os, mysql have to pick one of most selective index to use, leave another index not used at all. There is a great presentation on how index work in mysql: http://www.slideshare.net/vividcortex/optimizing-mysql-queries-with-indexes
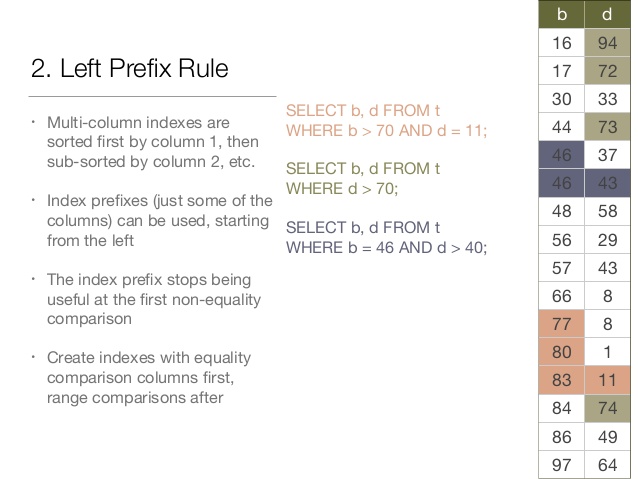
To index both column plat and os, then you have to create a multi column index to include both and even the ordering of the columns matters, index for plat,os and os,plat are different.
In elasticsearch, the inverted index are composable. You only need to index os, and plat separately. In the runtime, the both index can be used and combined to speed up the query. The filter plat='wx, os='android' can event be cached separately to speed up future querys.
The trick is called "roaring bitmap" (http://roaringbitmap.org/). Druid database has a detailed on article on how the magic works: http://druid.io/blog/2012/09/21/druid-bitmap-compression.html
There are two challenges to use bitset on the filter result. If we have 1 million documents, then for a given filter(for example plat='wx') there will be 1 million 1/0 result. How to represent the 1 million boolean result with minimum size is not a easy job.
This is a active research area to compress the sparse bitset. The filter result is sometime very sparse. For example user="wentao" will likely only have 1 hit out of 1 million documents. Storing nearly 1 million zeros will be such a waste. So the simplest compression is to represent a series of 1 or 0 using a compact form.
for example: 11111111 10001000 11110001 11100010 11111111 11111111
the last two words are all 1, so it can be compressed to
header section: 00001
content section: 11111111 10001000 11110001 11100010 10000010
Another challenge is to do AND/OR/NOT calculation for the compressed bitset. If we have to uncompress to do boolean logic operation, then the compression is not very helpful to save memory. Algorithms are invented to do the AND/OR/NOT on the compressed data.
The actual compression algorithm used in Elasticsearch (lucene is the underlying storage) is very complex and efficient. http://svn.apache.org/repos/asf/lucene/dev/trunk/lucene/core/src/java/org/apache/lucene/util/SparseFixedBitSet.java
The biggest benefit Elasticsearch can give us is to index a lot of columns separately. When doing the query, filters on different columns can be evaluated to bitset and cached efficiently. Then the filter result is AND/OR/NOT of the those individual bitset. There is no composite index in Elasticsearch, unlike mysql.
DocValues
In mysql, having a bunch of row ids filtered from the b-tree index, then load from the row store are very time consuming "random access" process. Similarly, having a bunch of document ids filtered from the inverted index, how to load other fields of those documents efficiently?
There are 4 ways to load document values that in Elasticsearch, take field "user_age" as example:
- Using _source "stored field", the document is stored as json, need to parse and get the field "user_age"
- Using user_age "stored field" if it is stored
- If user_age is indexed in inverted index, Elasticsearch will un-invert the index to form a document_id=>user_age mapping in memory (called "field cache"), then load from the "field cache"
- If user_age is docvalues, then the field can be loaded from docvalues file
DocValues is a real game changer here. It turns Elasticsearch into a valid player in the analytical database market. DocValues is a column-oriented data store, optimized for batch loading.
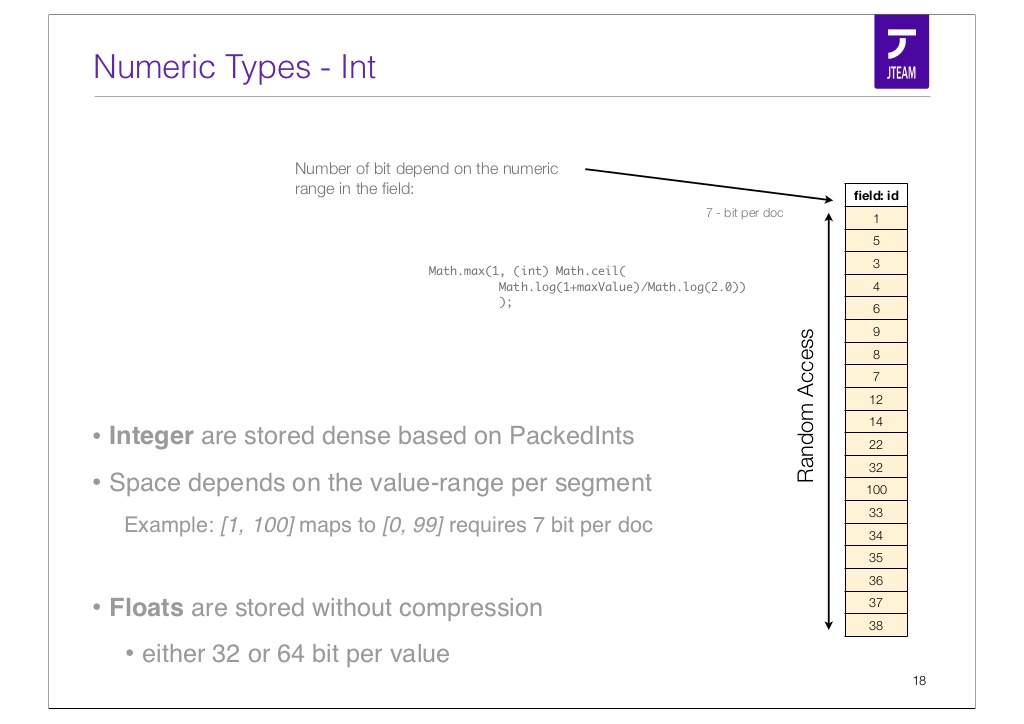
Above is how a int typed field gets stored on disk. There will be separate file for each DocValues field, within the file, values of documents are stored continuously. Each document occupy a fixed size to store its value of that field. So the memory mapped file looks like a array in memory, seek to the values of certain documents is a very fast operation. Batching loading a continuous documents is also very fast sequential read operation.
There is a very good video on DocValues:
- video: https://www.youtube.com/watch?v=JLUgEpJcG40
- slides: http://www.slideshare.net/lucenerevolution/willnauer-simon-doc-values-column-stride-fields-in-lucene
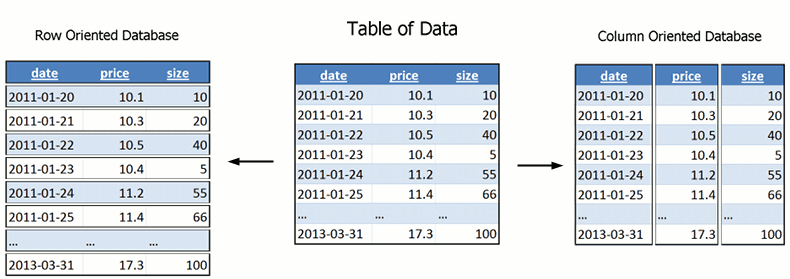
Mysql is a row oriented database, which means the rows are store one after another, each row has all fields in it. In row oriented database, there is no good way to load values of just one column out of 100. In column oriented database, it is very easy to just load the needed values. Also the column oriented layout is good for cache of CPU, as the values read is the values to be computed.
Compression: bit packing
It is worth mentioning, Elasticsearch also compress the stored DocValue. One of the technique is called bit packing. Using bit-packing numeric values can be stored with less disk space. The key observation is despite some int are large, the range of serie of ints are very close to each other. For example:
101, 102, 105
If we subtract 100 from the value, it become
1, 2, 5
then those values can be stored with less on disk space.

Compression: dictionary encoding
Store repeated string values in doc values will not store the same value again and again. Recall there is TSUID in opentsdb, the idea is metric name is very repeative and long (many bytes), instead of store the metric name on each data point, we translate the metric name to a numeric value to save disk space. Elasticsearch DocValues will do the translation internally for us, there is no need to do the optimization trick in application layer.
For example, we have 3 documents
doc[0] = "aardvark"
doc[1] = "beaver"
doc[2] = "aardvark"
It will be stored as
doc[0] = 0
doc[1] = 1
doc[2] = 0
term[0] = "aardvark"
term[1] = "beaver"
Block Join
It is also called nested documents or document block.
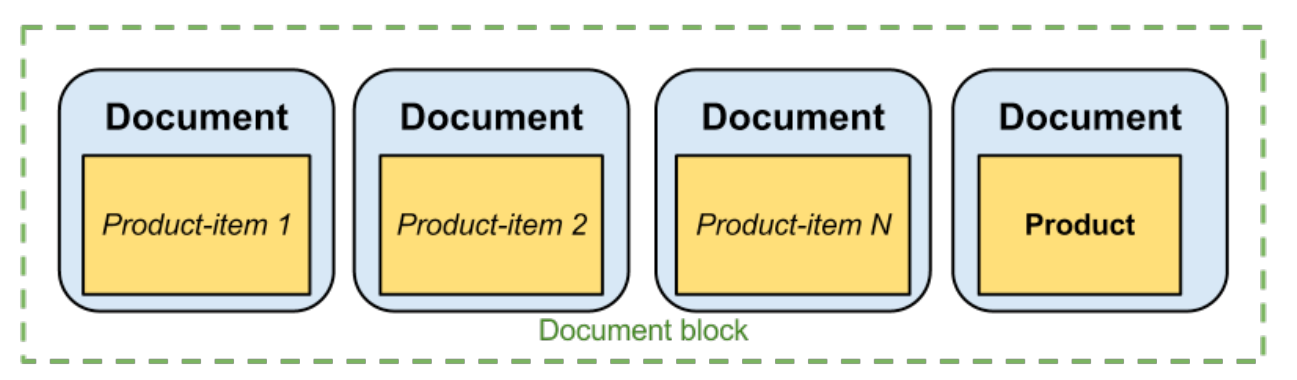
This is how it is indexed
curl -XPOST 'localhost:9200/products/product' -d '{
"name" : "Polo shirt",
"description" : "Made of 100% cotton",
"offers" : [
{
"color" : "red",
"size" : "s",
"price" : 999
},
{
"color" : "red",
"size" : "m",
"price" : 1099
},
{
"color" : "blue",
"size" : "s",
"price" : 999
}
]
}
What nested document can give us is 3 fold goodness:
- The ability to control the on disk layout of documents. If we index a bunch of documents as nested documents of one parent, they will be stored physically next to each other. data within a time range is accessed together most of time, it makes sense to pack data within a time range together as a series of nested documents. Nested document is working like clustering index in mysql
- Parent documents count is much less, so the inverted index lookup can be faster for parent document
- We can pull up some common fields to the parent document so that we do not need to repeat it in nested documents. For example, data for same application can have a app_id in the parent document, and in each data point nested do not need to mention app_id again
Index as partition
Compare to mysql
- mysql => database => table => rows
- elasticsearch => index => mapping => documents
At first glance, you might think index=database, mapping=table. Actually mapping is NOT physically isolated from each other. In reality index is ued like mysql table to physically partition the time series data, for example, we have 3 days of logs, then we create 3 indices:
- logs-2013-02-22
- logs-2013-02-21
- logs-2013-02-20
When we search we can specify the indices included in the scope to speed up the query:
$ curl -XGET localhost:9200/logs-2013-02-22,logs-2013-02-21/Errors/_search?query="q:Error Message"
Notice in Elasticsearch we can partition the data to time based indices, but there is no built-in support to select the indices for us based on the time range filter. Unlike postgreql, we can SELECT * FROM logs WHERE timestamp > xxx AND timestamp < yyy without knowing there is actually 3 physical tables beneath the logs view.
Distributed Computation
Most of the goodness is built-in the underlying lucene storage engine. But the distributed computation part is authentic part of Elasticsearch. Having elasticsearch built the distributed part for us, so that we do not need to shard our database, we do not need to send queries to "related" nodes and collect the results back for further aggregation. All of these things have been taken care of.
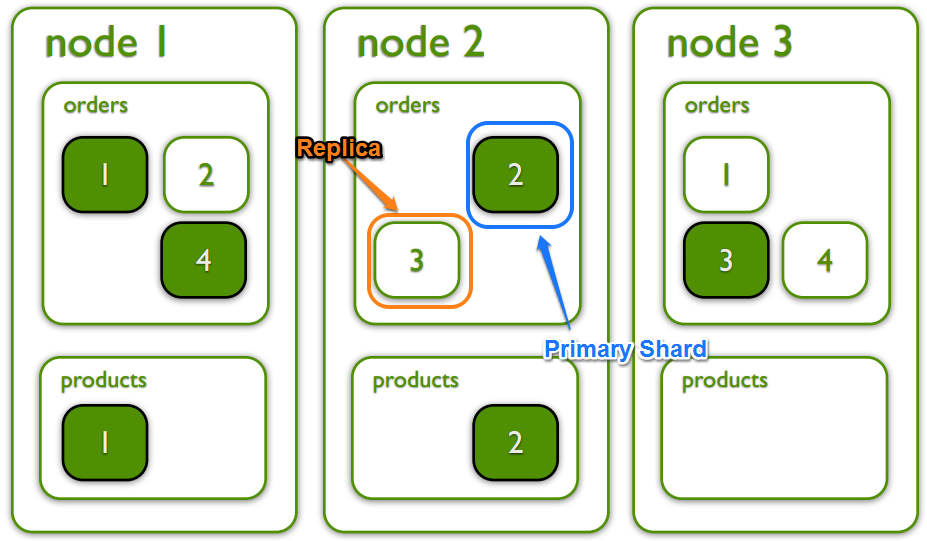
The sharding is not perfect. Master is not using zookeeper, makes it prone to split-brain problem. From crate.io blog we can know the aggregation can be improved or we can use crate.io instead (which builds on top of Elasticsearch): https://crate.io/blog/crate_data_elasticsearch/
Elasticsearch currently supports the HyperLogLog aggregations, whereas Crate.IO supports accurate aggregations. Also Elasticsearch scatters the queries to all nodes, gathering the responses and doing the aggregations afterwards which results in high memory consumption on the node that is handling the client request (and so doing the aggregation).
Crate distributes the collected results to the whole cluster using a simple modulo based hashing, and as a result uses the complete memory of the cluster for merging. Think of it as some kind of distributed map/reduce.
But nevertheless, Elasticsearch has a distributed computation layer that works.
Map/reduce story
Elasticsearch has very good story on Map/reduce as well. There are two ways to do that
- Use Elasticsearch distributed computation as a map/reduce engine, you plug script into the calculation process
- Use Elasticsearch as a data store with good filtering support, build the distributed computation layer using Spark
This is how Elasticsearch can be used as RDD in spark:
// Set our query
jobConf.set("es.query", query)
// Create an RDD of the tweets
val currentTweets = sc.hadoopRDD(jobConf,
classOf[EsInputFormat[Object, MapWritable]],
classOf[Object], classOf[MapWritable])
// Convert to a format we can work with
val tweets = currentTweets.map{ case (key, value) =>
SharedIndex.mapWritableToInput(value) }
// Extract the hashtags
val hashTags = tweets.flatMap{t =>
t.getOrElse("hashTags", "").split(" ")
}
The filter is push down to be executed by Elasticsearch, the aggregation part is done by spark.
For using Elasticsearch itself as a map reduce engine, the feature is called "Scripted Metric Aggregation": https://www.elastic.co/guide/en/elasticsearch/reference/1.6/search-aggregations-metrics-scripted-metric-aggregation.html
Compared to nosql database like Mongodb, who claims to support map/reduce using javascript. I think plugin java code into Elasticsearch/lucene is a much better interop story than integrate a c++ database engine with a javascript engine.
Future: Off-heap
Elasticsearch is using a lot of Java Heap to cache. One important future direction is to move a lot of cache off the heap. Here is video on this effort forked from Solr (Another lucene based search engine):
- video: https://www.youtube.com/watch?v=dDywZDQJQ3o&index=43&list=PLU6n9Voqu_1FM8nmVwiWWDRtsEjlPqhgP
- slides: http://www.slideshare.net/lucidworks/native-code-off-heap-data-structures-for-solr-yonik-seeley
Future: SIMD
Elsaticsearch is limited by the JVM, so that leveraging SIMD cpu instructions to aggregate data faster is hard to implement. There are smart guys working on bring SIMD acceleration into Elasticsearch, and have very promising results:
- video: https://berlinbuzzwords.de/session/fast-decompression-lucene-codec
- post: http://blog.griddynamics.com/2015/02/proposing-simd-codec-for-lucene.html
Success Stories
There are two company using Elasticsearch as time series database from my knowledge. There must be many more companies using it, but I was not aware of.
- Bloomberg: http://www.slideshare.net/lucidworks/search-analytics-component-presented-by-steven-bower-bloomberg-lp
- Parse.ly: https://www.elastic.co/blog/pythonic-analytics-with-elasticsearch
Because there are many more people using Elasticsearch as a analytics database instead of search engine, the company behind Elasticsearch is now called "Elastic" without search.
As we can see from above, there are a sorts of optimization has been done for you by lucene and elasticsearch. We can make a list to compare:
- Opentsdb TSUID: opentsdb compress the metric name to TSUID by using a dictionary. This is optimization is FST to store inverted index in lucene. If the long string is not index but DocValues, lucene will also use dictionary encoding to compress it.
- Opentsdb HBase Scan: opentsdb is using the physical layout of hbase data file to scan sequentially. In lucene this is done by columnar store DocValues file.
- Opentsdb compaction: opentsdb compact data points of a time range into one column of one row, to reduce the storage size and speed up the scanning. This can be optimized using nested documents of lucene.
- Postgresql time based partition: postgresql can create table for every day, then combine the tables as one view. Elasticsearch can also do the time based partition, but wehn querying the application level need to be aware of the time range and actively select the indices (like postgresql partition table) to use.
- RDBMS b-tree index: inverted index is fast, and the DocValues is column-oriented unlike row-oriented rdbms which can not utilize the b-tree index when rows to fetch is huge.
- Mysql covering index: Elasticsearch does not support covering index. DocValues can remedy the pain.
- Mysql clustered index: Using clustered index can store related rows phyiscally together to speed up query. Elasticsearch can use nested documents as clustered index.